Joseph K. Myers
Friday, March 12, 2004
The server consists of special modules. These modules provide the functions of a server, each module being an independent algorithm or "kit," as small and efficient as possible.
The module paradigm is not superior to a monolithic, complex design. The truth is that the server's modules--and any program's--are fictious; when applied in one piece, they form a monolithic item.
The ideas of modularity, toolkits, or object-orientedness are only cups that designs are poured into, to make them drinkable. The real thing is as complex as you like it.
Rational thinking would have to conclude in complete disagreement with the statement that complexity is Bad.
Finally, the server is not about HTTP design, but server design. HTTP is ignored when it is wrong.
Like abortion is a wrong right, so can too be anything.
The big win for pretending like pieces of a bigger cake are like individual pies is that you can do abstraction.
Reading bytes is abstraction. Reading lines is abstraction. Reading headers is abstraction.
Rather than being a system call, the server reads headers through a module call, if you want to call it that.
This module is the take-header module.
If you are familiar with the semantics of read(), then you will be familiar with the semantics of this one.
read_headers(int fd, struct headers *h);
The difference is that a length is not returned of the number of headers read. Instead, a status is returned.
Zero corresponds to the structure *h being filled with an amount of headers equal to h.n;
One corresponds to the end of possible input.
Negative one corresponds to the same meaning as negative one for read()--check the value of errno; anything except for EAGAIN should probably be taken to signify an error.
This abstraction falls short, however. Bodies are also sent, intermingled with headers in general HTTP transactions.
In the computer operating system:
The HTTP server runs as http (not httpd), under no particular user. In order to run user programs under the user's own identity, the server needs to be setuid.
In control of the server:
A SIGHUP (hangup) signal can be delivered to the server, which causes the server to close its passively open port. The server itself gracefully exits after completing current connections.
To atomically replace an old server with a newly configured http process, simply start the new process and deliver SIGHUP to the old process.
This is better than to dynamically reconfigure memory of a running process.
To force any server to exit, send an ordinary SIGINT.
In file permissions:
For executable files, only the owner permissions are checked: S_IRUSR, S_IWUSR, and S_IXOTH.
For readable files, only the world permissions are checked: S_IROTH, S_IWOTH, and S_IXOTH.
6-2-04. As an additional security feature, the server runs programs not as the owner of an executable file, but as the group. The program can't write unless permissions are set to allow the group to write to them. This allows your own files not to be trashed by a program, just like running a program under separate user IDs keeps all the server's users from being trashed by one program.
5-4-04. Title: surfing the web. Wouldn't it be nice if servers all worked the same (on the outside, of course, not the inside) so that you could have a consistent experience and do what you wanted to do on the internet?
Questions and answers.
5-22-04. How many simultaneous connections can the server serve, and in how much memory?
It depends on the memory and resources your operating system consumes upon connections. The server itself uses a constant amount of memory for every connection, whether it is busy or idle. If you run the server with memory allocated for a certain number of connections, this will limit the load that your server will bear, because that amount of connections will not be exceeded.
Generally, each connection consumes 16 KB for inbound server memory and 16 KB for outbound. There may be another 16 KB added for a third use, so the memory of the server for each connection should be estimated as 48 KB. This means that 100 connections capable of being serviced will need a server running with about 5 MB of memory. Correspondingly, a server with 10,000 connections capable of being serviced should have about 500 MB of memory. Either way, the server won't use more or less than was allocated for it to begin with.
You can also compile the server to use a lot less than this, but depending on the nature of most of your connections, you shouldn't have to change anything.
5-22-04. How does CGI work, or how do the programs work that the server can run, if they aren't the same as CGI?
The server can process all of the data into files for each connection to an executable program. Subsequent requests don't come through until the last request has been responded to. (Up to the next normal buffer amount, usually 16 KB, of data from a client can always be read, regardless of the state of the connection.)
The server doesn't need to create a file for requests that completely store within its buffer, so requests with a minor difference in size, which exceeds the buffer amount, may show less than equivalent high performance.
All the server's simplicity with programs is designed to make the programs run faster, and be able to process requests from all clients without starting. A simple program can act like a CGI program by sending back headers. There is exactly one condition for simple CGI--if the output has a colon preceding the first occurrence of whitespace.
The server has an extremely good system for balancing the capability and efficiency offered to programs which are specifically implemented for the server. A program has the choice to send back another HTTP request, which may be recursive, as its response to the server. This lets the full function of the server deliver the content generated by the program, or completely invoke another program in a second step to delivery of the finished operation. It also lets any redundant values generated by an ordinary kind of program be efficiently reused from the same file until the program knows it needs to generate the file again. In essence, this option lets the program serve as its own agent for providing an infinite number of special responses and operations over HTTP to the client, through the interaction of the server, which functions as a competely new kind of API.
The second function is to be an nph program--but the connection must be closed after the program's output is finished, because the program is allowed to take over the negotiation of the connection. This also allows invalid HTTP behavior, at the discretion of the program writer. This kind of behavior is triggered by output which does not begin with a colon before the first whitespace, but which is not an HTTP request.
With all of these functions, the server is only limited by the limitations of HTTP, such as not being able to put a current request on hold or change the order of pipelined requests.
However, this doesn't mean pipelining is a shortcoming. Pipelining requests is the fastest way of performing operations, and it is easy for efficient negotiations and changes to be made through a second connection.
5-26-04. The libraries are 1) mime.types and file extension recognition. 2) connection buffering code--receiving, caching, and redelivering data. 3) http header interpreter. 4) process threading.
The way that 2) works is for the server's own memory to keep the whole request stored, up to 16 KB, or the buffer size. If the header fits, but the request doesn't, then the top of the buffer is written to the connection's file (opened a single time when the server launches), and the tail of what has been read is kept in the buffer. When the whole request is finished, there may be part of an additional request within the buffer following the tail of the request. In fact, the server may continue to read from the client during any stage, until this entire buffer is filled. This prevents deadlock with simple clients submitting small payloads, which may not read until they finish writing.
When the server needs to deliver this either back to the client (in a TRACE request) or to a program, the sending buffer allocated for the connection is used to pass on the request.
Note that this plugs into a basic piping mechanism, which can send other content compiled with optional headers at the begining and the contents of a file in an ordinary HTTP response.
5-27-04. Why is the server better?
The server is available in two versions: one, a not-very-useful version, provides HTTP access only to documents. The other provides HTTP service that can be extended by running your own programs through an interface analogous to CGI, but better than CGI or any other web service.
The server doesn't need any configuration. To provide service to domains through port 80, you need only do http 80; to provide service through any other port, you need only do http for that port number. All of them can run at the same time.
Other servers consume a significant amount of startup time. Other servers can't usually be restarted at any time without putting your sites offline for a while. This server always will keep service online, even while you change it--even while you are completely recompiling it. This server always stays online and cool, until you decide to close the socket.
30 servers, each servicing 53 connections, can be started up in 0.03 seconds.
Compare this to mathopd--which takes 0.30 seconds to do the same, or Apache, which takes 45.310 seconds. thttpd consumes 0.120 seconds.
The size of thttpd is 94 KB, mathopd is 86, and Apache is 393. The size of the server is 29 KB.
Now let's evaluate all the servers as to their internal processing speed. As file sizes get larger and larger, the download speed of all the servers should get closer and closer together. The servers don't have to do serious work to process the request while a huge file is being transferred--so instead, the rate depends on the operating system and the network.
However, a more efficient server should be able to maintain high traffic flow with small-sized requests, and be able to reach the maximum speed limit sooner than the other servers. It should have a big advantage over them, before the graphs draw closer together with larger and larger files.
The graph shown displays the time for 200 pipelined requests. Among each group of 200, the requests are all the same size, but each new trial advances the requested file size by 512 bytes.
There are 65 trials in all, from 0 bytes to 32,786. Apache is port 8080, mathopd is 8081, and the server is 8083.
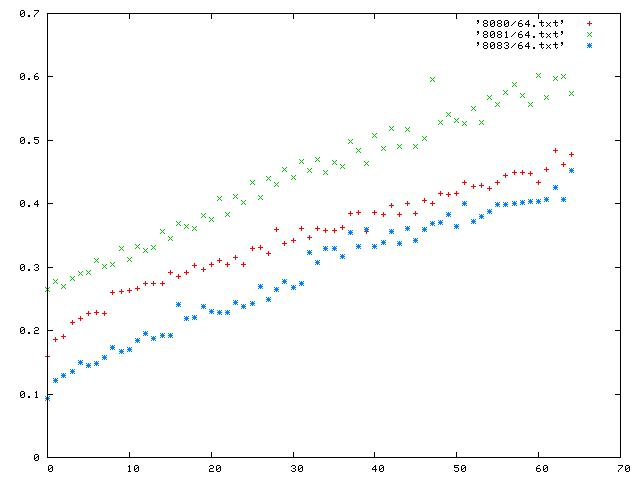
A second graph shows the absolute rates achieved by the servers; a higher rate produced means more efficent responses to small and large request sizes. The x-axis is the same, and the y-axis shows bytes/s (for the total flow of server, including headers that are created).
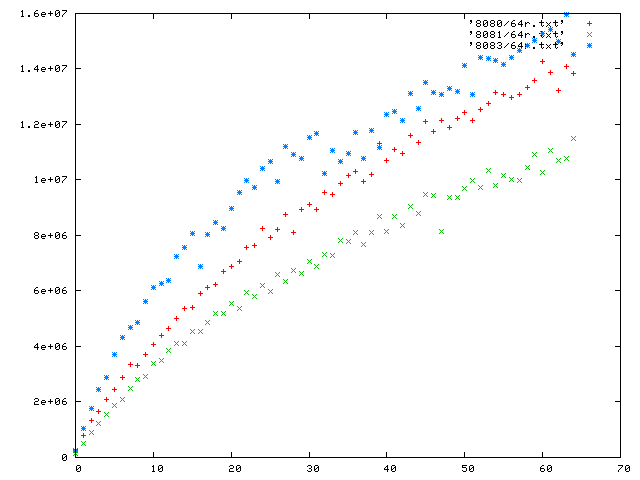
The server can balance all connections simultaneously with each other, so it never waits on an idle connection, but services many others. Unlike other servers, this server doesn't have to spend energy making a sophisticated effort to accomplish this. This is because the structure that the server creates for connections automatically controls high performance links as well as low performance links.
Just watch how the results for several servers come out. Each one is trying to provide a web page full of images. There are 37 files in order to load the page. The HTML file is 9,030 bytes in size, and the other files are images.
The sizes of the files are in this table:
33695 9030 30146 36881 93218 96612 23363 28862 16127 40180 10677 146215 50995 181123 36002 117759 133405 34969 91233 75074 20614 33156 187888 179881 152058 200726 158672 174698 53104 23173 22661 37673 23699 25975 200362 105251 29684 Sum: 2914841 Avg: 78779
We take a sample of size 30 for the download time of the whole page, with all of the images. We do this for each server.
For the average download time of the sample, mathopd gets 0.1880171 (s=0.00644598586), Apache gets 0.1664001 (s=0.00612336459), and the server gets 0.1624391 (s=0.0057230021) seconds.
Take a look at the advanced Multipart Internet Mail Extensions recognition system, and the clockwork, state-of-the-art input recognition system.
The server also implements a much fuller, freer, and better-designed pipelining, streaming, and flow system.
See from this coolness meter how the better algorithms of the server result in less CPU time used for processing a connection:
Legend: CPU time for answering and fulfilling a 300-length benchmark with ApacheBench (document length 1642 bytes).
Running with a single client (the CPU time includes time of the operating system):
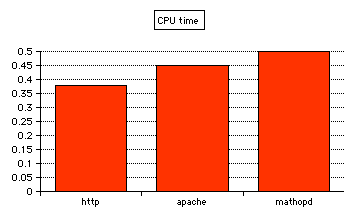
http = 0.38 s, apache = 0.45 s, mathopd = 0.50 s
With 10 clients and a length of 3,000, here are the times:
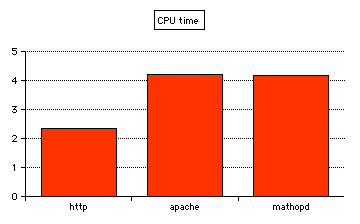
mathopd = 4.18 s, apache = 4.22 s, http = 2.36 s
The server--because it has better algorithms--handles higher loads much better, and achieved a rate of 643 requests/s (1132 KB/s), compared to 467 (898 KB/s) (Apache) and 464 (851 KB/s) (mathopd).
If we take into account only the CPU time of the server program, and not of the system, then the server's performance is even greater. Apache takes 1.870 seconds, and http takes only 0.510 seconds.
The performance difference is even greater in real life, where larger amounts of data are submitted in each request header.
Requesting a 4356-byte thumbnail image (thumb_misty-5.jpg), accompanied by a header just as many ordinary browsers would send, we see these results:
For requesting 24 times by 160 clients, (3840 times total), with a header size of 682 bytes:
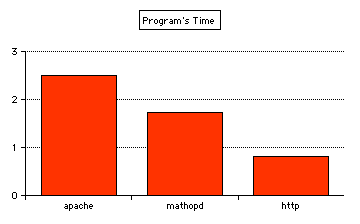
apache = 2.490 s, mathopd = 1.720, http = 0.820.
Finally, how well does the server respond to error conditions, and the denial of service attacks which they might cause?
Changing all of the requests in the last test to make them be 404 errors, the server takes only 0.240 s, while Apache took 4.700 s, and mathopd took 1.520 s.
Changing all of the requests in the last test to make them be malformed, dangerous security errors, the server takes 0.280 s, while Apache took 4.240 s, and mathopd took 1.620 s.
We can see that as the size of headers accompanying requests goes up (as it might as more complicated requests become common), the efficiency of the server is more important. The server is more than twice as fast in processing request input for large requests than the nearest similar program. When larger links are available, the faster server can provide more bandwidth. It is not valid anymore to use the excuse that, "My 200 MHz PC can soak the entire connection, so I don't need a faster webserver."
The server never uses a dangerous chroot jail. Instead, the server always ensures that permissions are followed on the files which are served. Risky executable files, as well as alias names and dots (like %61%62.txt, or /../.bashrc) are rejected as valid file names.
You'll always get the same response--404 Not Found--if a document is restricted, as if it is unavailable, or non-existent. Other servers say "Forbidden" or "Permission Denied," which proves that it exists on the server; it may then be subpoenaed in court.
The server never uses more than a predetermined amount of resources.
The server can be controlled the same way as an ordinary program.
The server allows you to use encoded filenames, thus permitting foreign files--and any filename capable of being encoded and sent on the internet--to be served from your computer.
The server doesn't log requests by default, as others servers often do; other servers allow arbitrary material to be stored in log files on your computer by anyone on the Internet.
The server keeps all HTTP/1.1 features under control. The server properly supports resumable downloads.
The server lets you use your existing file system online, as well as links--undifferentiated.