At first I made an extremely complicated combinations and permutations based mechanism for minimizing the number of conditions and comparisons to recognize any file extension.
This literally took minutes of time when analyzing more than three levels of characters or so, and later I realized that a simple sorted-order based switching mechanism is more efficient.
I haven't optimized the second technique very much (i.e., to stray away from explicit length checks at every point to avoid memory faults, when a more efficient implied strategy may be guaranteed to work as well), but here are the results of how well they work.
| File extension | System (permutations or switches) | Compiler optimization | Recognition rate (recognitions/sec) |
|---|---|---|---|
| jpg | permutations | none | 1,730,100 |
| jpg | permutations | -O3 | 3,355,700 |
| class | permutations | -O3 | 11,111,110 |
| zip | permutations | -O3 | 1,358,690 |
| jpg | switches | none | 3,759,390 |
| jpg | switches | -O3 | 8,620,680 |
| class | switches | -O3 | 8,196,720 |
| zip | switches | -O3 | 12,500,000 |
Doing a more useful test--checking a randomly-generated extension list--we see that with optimization, the switches technique is 10,526,310 resolutions of file type per second.
The permutations mechanism returned a result of 3,030,300.
The randomly-chosen list of extensions (with html added for good measure) is:
cdf xls pbm kar jpg snd mp3 dir nc etx djvu html
Finally, it takes 40 seconds of time to compile the most minimally analyzed catalog of file types using the permutations technique. It takes an insignificant period of time for the switching technique; in fact, the switch list is created by a really neat JavaScript program.
(This program has been included in listswitch.c for use without JavaScript.)
As you can see, there are also differences in the algorithms themselves. For the permutations algorithm, zip is in last order, so essentially it is the slowest of them all (.c is the fastest file extension: 13,157,890 recognitions/sec).
For the switches algorithm, it doesn't make that much of a difference (.c would also be approximately one of the fastest file extensions, but it hardly differs in the rate of recognition from .zip).
Last of all, I suppose it is easier to use the second technique, because it goes directly from an original mime.types file in order to produce all of its output.
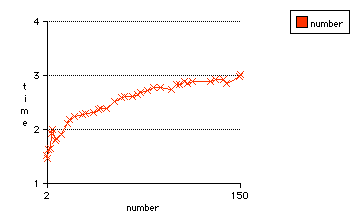
An interesting result is to see the type of function f(n) to which file extension recognition is like as a function of the number of recognizable file extensions.
It is nonsense to "recognize" less than two file types (and the recognition algorithm doesn't supply any code), so we take n > 1.
The graph shows the time for recognizing (or voiding) 12,000,000 unknown file extensions vs. the number of file extensions which are defined in the switcher.
4-24-04
For comparison, publicfile, which only recognizes nine file types, uses a file extension recognition system which the author should be ashamed of. Recognizing 12,000,000 file extensions consumes 5.9 seconds (utime, unoptimized), or 5.1 seconds (utime, -O3 optimized). If the time had been 5.0 seconds, then the rate would have been only 2,400,000 recognitions/s, and yet it is slower than that.
This mechanism, which recognizes any number of filetypes, and reduces logarithmically in the worst case in recognition time vs. number of known filetypes, is easily five times faster, even with 154 filetypes. If you multiply 5 by 154/9, then the improvement is by 85 times.
Obviously, the creator of publicfile did not think this was important.
In addition, this mechanism is versatile enough to be compiled directly from a mime.types file.