Joseph K. Myers
The performance of the previous header-parser was extremely good.
When I rewrote it, I decided to do comparisons. I was fairly sure my new ideas were good, but I wanted to make sure. The new version doesn't use pointers at all: it uses numbers. My original experience with this was in making input transformation objects, which worked faster and better this way.
Unfortunately, no other servers to my knowledge can have their header parsers extracted for testing like this.
The graphs are all showing the performance of the header-parsers in parsing 20,000 HTTP request-style headers.
The number of lines within each header is shown along the x-axis. The size of a header with one line is 28 bytes, for example, or with 20 lines, it is 541 bytes.
Time in seconds is shown along the y-axis.
The name of the program is given in the title of the graph, with an indication of whether or not the program is compiled with optimization.
All of them were compiled with gcc-3.3, on the same machine.
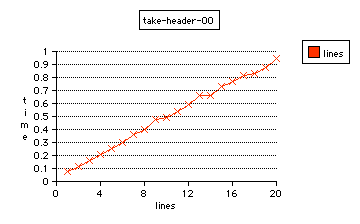
take-header, the first header parser (truthfully, about the fourth edition that I have written as an an algorithm in C for interpreting HTTP-like headers); with no compiler optimizations
take-header, the identical program, with -O3 compiler optimization
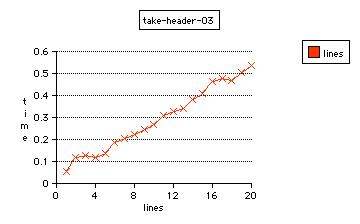
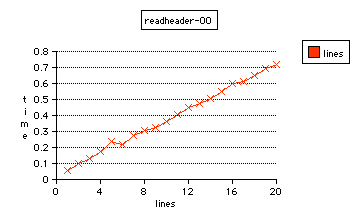
readheader, the newer parser; without compiler optimizations
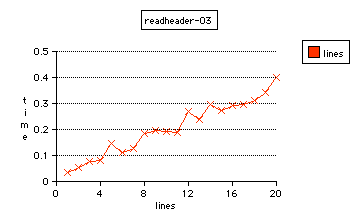
readheader again, with -O3 compiler optimization
Without optimization, take-header can accept 20,000 single-line headers (560,000 bytes) in .078 s (709,858 B/s), or the same number of twenty-line headers (10,820,000 bytes) in .943 (11,476,392).
readheader can do this in .056 (10,044,483) or .719 (15,041,921), respectively.
With optimization it is, .0546 (10,273,344) and .536 (20,186,341) for take-header, or .0348 (16,112,790) and .401 (27,008,340) for the readheader.
In my judgment, these results show that both header parsers are much better than other algorithms which are not as carefully designed. These header parsers are designed for abstract input-output with full buffer capacity, and work for any predetermined settings of maximum buffer size or limiting number of lines per header.
Between themselves, readheader performs 34% better, besides being more efficient to program by eliminating the archaic \0 methodology of strings, and by eliminating the need for any strlen() calculation.
4-4-04
The conditional expressions and order of operations can be further reduced with a form of optimization mathematics, and use of Venn diagrams.
(This is not like optimization compiling. On the contrary, if the optimization mathematics were the same as opimization compiling, then the result could be less further optimized by a compiler. However, it is almost always the case that what has been mathematically reduced to least cases, least variables, and least computation, is also more compiler-optimizable.)
Since this is the final version of the header parser mechanism, its name is only the library name (header.txt, header.c, and header.o). Therefore, the name that the test goes by is "headerusage," the example that is written showing how to use the mechanism.
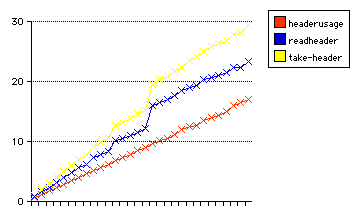
Shown in the two graphs are all three parsers in comparison. The first graph is with no compiler optimization; the second is -Os optimized.
Both graphs are a range of header lines from 1 to 30 on the x-axis (every parser is a priori limited to 20 lines--the values 21-30 are data of interest for study only).
The y-axis in both cases shows time for reading and parsing 200,000 headers of how many indicated lines.
A line is 49 bytes, which is the statistical average line length of HTTP headers. Thus, the shortest header is 50 bytes; the longest, 1471. The total of input for the shortest headers is 10,000,000 bytes; for the longest, 294,200,000.
LF (ASCII 10) is used for line breaks since the lines are Unix lines. Neither of the second two parsers are affected by the form of line breaks, except in the number of bytes to be analyzed. In general, LF is faster and forms a more determinant line-ending mechanism.
Multipliers are generated with rp.
All testing was done on a 1999 model iMac 333 MHz computer, running Mac OS X 10.2.8, kernel version 6.8. The compiler used was gcc version 3.3 20030304 (Apple Computer, Inc. build 1493).
This is the first graph, showing all three parsers being timed within equivalent unoptimized implementations.
The data for this graph are in take-header, timereadheader, and headerusage.
A brief summary table to accompany the graph:
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| take-header | 9.84 | 21.72 | 29.28 |
| timereadheader | 7.80 | 17.65 | 23.27 |
| headerusage | 5.70 | 11.16 | 16.93 |
This second graph shows all three parsers in the same implementations as before, compiled with CFLAGS=-Os.
The data are in take-header-Os, timereadheader-Os, and headerusage-Os.
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| take-header | 6.17 | 14.44 | 18.74 |
| timereadheader | 4.49 | 11.12 | 13.51 |
| headerusage | 3.10 | 6.14 | 9.21 |
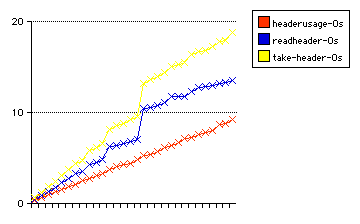
It is interesting to note that the time differences between the final product version and timereadheader are due in the main to more efficient system and clock time. If user time only is observed, you will see almost the identical result.
For instance, with 500,000 8-line headers read and parsed, we have a time value of
13.43 real 3.45 user 3.25 sys
for timereadheader-Os, and
11.26 real 3.20 user 1.60 sys
for headerusage-Os.
The differences in the patterns of the two graphs in -Os (headerusage-Os does not show a jump where both the others do), as well as the differing system time but similar user time, lead to a re-evaluation.
The discovery of a difference in the respective definitions of buffering size solved the problem. It would have been hocus-pocus to consider that that large a difference could have existed without more to substantiate it.
The jumps were caused by a need to rebuffer overflowing data; a larger buffer size obviated this in many cases.
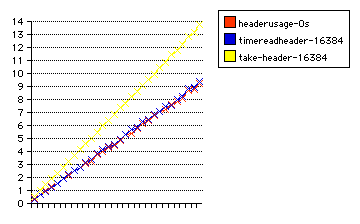
The new graph is made with the same buffering system for take-header and timereadheader which is used in headerusage. The -Os optimization is used, and the data for headerusage are the same as were used before.
New data sets: take-header-16384 and timereadheader-16384.
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| take-header | 4.58 | 9.09 | 13.81 |
| timereadheader | 3.15 | 6.30 | 9.38 |
| headerusage | 3.10 | 6.14 | 9.21 |
The revised graph is this:
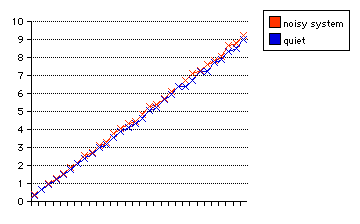
We can compare the times of the identical program (headerusage-Os) when running on a quiet system (single-user booted) or a fully running, multi-user system.
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| quiet system | 3.00 | 5.94 | 8.97 |
| noisy system | 3.10 | 6.14 | 9.21 |
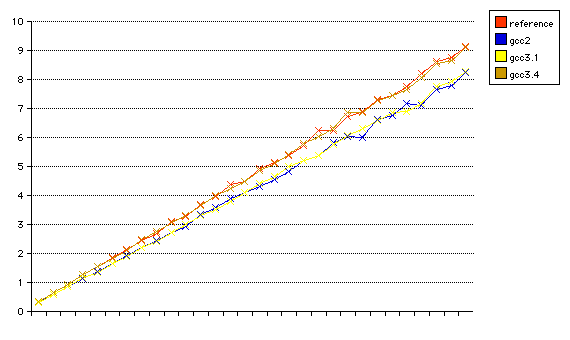
We can also compare the performance of the headerusage code when compiled with four versions of the gcc compiler. All had compiler flags set to be CFLAGS="-O3 -funroll-loops".
Here in the graph, the terms are defined as
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| reference | 3.10 | 6.14 | 9.21 |
| gcc2 | 2.72 | 5.37 | 8.23 |
| gcc3.1 | 2.74 | 5.38 | 8.26 |
| gcc3.4 | 3.08 | 6.02 | 9.10 |
Also, we can see how closely bound the process is to the computer's subsystem speeds or to the computer's processor speed. We compare a 400 MHz processor to the 333 MHz processor of the other tests. For both, the headerusage-Os standard is used.
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| 400 MHz | 2.51 | 4.93 | 7.42 |
| 333 MHz | 3.10 | 6.14 | 9.21 |
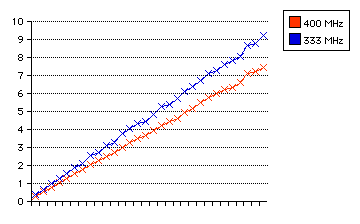
7.421158/9.208806 is .805876, and 333/400 is .8325, so there is only a 2.66 absolute percentage difference from the two times being perfectly correlated to processor speed.
When all the information in each header (when it is HTTP headers in particular that are being processed) is processed by the HTTP server itself, and used to respond to a request, an additional amount of time is used.
This particular step essentially represents the true performance of the server minus any actions which are taken to perform the response itself.
Rather than being a measure of the performance of a server at making responses, it is a measure of the performance of a server at being a server.
That is, it is a measurement of how fast a server is in regard to receiving and understanding what a client says.
This is useful to know when the server itself is used between a server and a client, or even between two servers; in this case, it is most important how fast the server translates all the information that is communicated, because another process is involved in talking back to the client, and another process is involved in taking specific actions on behalf of the client.
To make this process go fastest, the intermediate server must catalyze the link which it forms in the pipe between programs. It could be working point-to-point on the Internet, waiting to receive connections through a network for an off-network database, or connecting many other jobs, and making them easier to do well.
The graph shows the time used after the HTTP server has interpreted the instructions within each HTTP header. Otherwise, the test is the same as before. The comparison line is of httpusage-Os, and the scale of the graph is the same as for the revised graph optimized with -Os.
| name | 10 lines (time in sec) | 20 lines | 30 lines |
|---|---|---|---|
| headerusage-Os | 3.10 | 6.14 | 9.21 |
| headerusage-interpret | 3.89 | 7.70 | 10.71 |
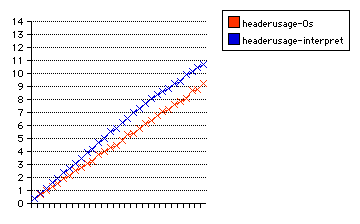
This shows extremely amazing performance, and the reason for it can be explained. The header information is recognized via the extremely quick listswitch program interface. This interface itself is described and analyzed in mime.types, because it also forms the recognition system for MIME types and file types.
Thankfully, it is as fast as a breath of air.
With optimization, headerusage performs at 31,947,681 B/s, or 652,306 header lines/s, or 80,073 headers per second of the statistically average HTTP header on the Internet, which has 8.1 lines.
This meets or exceeds the engineering goal of the program, which was 50,000 headers per second.
Secondly, to show a fair evaluation of the performance of the server itself, minus the account of the actions that are performed as a result to make an answer, we may take the time required for the information from the parsed header to be understood.
This is performed extremely fast, at an isolated rate of 196,580,094 B/s, or 4,013,760 header lines/s, or 492,707 headers per second, due to the interpretation mechanism which is used, and because of the accurate, efficient form which the header parser produces to represent the data.
jkmyers @ wichita.edu