Introduction
Performance of sort is 280 ms for sorting 1,048,576 items. This compares to 420 ms for qsort implemented on Unix systems, or 300 ms for an ungeneralized version of the same algorithm. At each step of development, sort was tested against all permutations of 5-character strings, and on a set of 100,000 elements from /dev/random.
The graphs at the end of the report show some optimizations as applied to quicksort on random data. Variance on the tests was reduced to almost zero. (For instance, every sort of 185,363 items should be 46 ms, with extremely small deviation; on the flip side of the coin, one can't hope for things to mysteriously get better.)
Some of the optimizations could only be invoked after the application of prerequisite optimizations. Elimination of a random pivot could only be used when treatment for preordered, forwards* or backwards, data had been reduced to a trivial operation. This is one case for an example of what was accomplished.
(*Comment on English usage: there is a difference between use of the s. That is backward refers to a backward thing, being an adjective, a characteristic of the subject. That is backwards refers more distinctly to the positions of what may be ordered. Similarly, towards is a directed word, while toward is descriptive. There may be some who say descriptive words are for both.)
When there was no ability to reduce somthing in such fashion without any loss, one could have decided to do something else--like to use a random pivot only where there were N > cost of generating a random pivot. This would require very careful analysis, however; savings like that may only be cutting off the lower end of your apron to sew it onto the top. There is only so much one can do in flying by one's own bootstraps.
It is very, very interesting to see how quickly a sort converges upon a solution. In recursion for a particular 1,048,576-element random sort, one observes that no recursive sort is ever called for a set of less than 3927 elements.
Programming an approach to sorting
There are simple things, and there are powerful things, and the simple ones make the powerful ones work, rather than being mediocre.
Context
Two header files are used for definitions, one for libraries, one for programs.
/* libsort.h */ #include <string.h> #include <stdlib.h> typedef unsigned char c;
/* sorter.h */
#include <errno.h>
#include <stdlib.h>
typedef unsigned char c;
void sort(c *, int);
enum {
MAX = 20971520
};
Interface
A shell program was designed to implement a sort defined in a library linked to the program. Some of the features are not designed for usability, but for efficiency in testing.
p N: Allocate N, read l <= N characters from fd 0; if l == N, allocate l, and perform int(max/l) sorts, copying for each sort into the second allocated space. (Where max is defined according to desired sorting analysis.)
p 0: Allocate and read for all input; perform one sort.
p: Perform as p 0, but write sorted input to output.
The source of the program is here:
/* sorter.c */
#include <math.h>
#include <stdio.h>
#include <time.h>
#include "sorter.h"
int main(int argc, char **argv) {
c *b, *b2;
clock_t m;
float r;
int i, j, l, p, z;
unsigned int n;
n = errno = 0;
if (argc > 1) {
if (sscanf(argv[1], "%u", &n) == 0) return 1;
}
if (n) {
z = sizeof(c)*n;
b = malloc(z);
if (n > 1 && (l = read(0, b, z)) > 0) {
if (l == z) {
b2 = malloc(l);
i = MAX/n;
m = clock();
for (j=0; j<i; j++) {
bcopy(b, b2, l);
sort(b2, n);
}
/* stdev of a sample mean is supposed to be
s/sqrt(n); we automatically assign s to be
1 ms, so we give significant figures based
on log10(sqrt(n)).
*/
m = clock() - m;
r = (float) m * 1000 / CLOCKS_PER_SEC / i;
p = (int) ceil(-log10(r) + log10(sqrt(i))) + 1;
if (p < 0) {
r -= (int) r % (int) pow(10, -p);
p = 0;
}
printf("%.*f\n", p, r);
free(b2);
}
}
}
else {
z = sizeof(c);
l = i = 0;
if (b = malloc(z))
while ((l = read(0, b+i, z-i)) > 0) {
i += l;
if (i == z) {
z *= 2;
if (b2 = realloc(b, z))
b = b2;
else
break;
}
}
if (!errno) {
sort(b, i/sizeof(c));
if (argc == 1)
write(1, b, i);
}
}
free(b);
return errno;
}
Baseline
The initial quicksort algorithm works like this:
/* libquicksort.c */
#include "libsort.h"
void swap(c *a, c *b) {
c t;
t = *a;
*a = *b;
*b = t;
}
void sort(c *a, int z) {
int i, k;
if (z <= 1)
return;
swap(a, a+rand()%z);
for (i=1,k=0; i<z; i++)
if (a[i] < *a)
swap(a+i, a+ ++k); /* Cleopatra, I'd like to say:
swap(a+i, a+++k); */
swap(a, a+k);
sort(a, k);
sort(a+k+1, z-k-1);
}
In this program, and in following ones, integer overflow for sort length is ignored. The effect of this is that 2^31-1 elements is the maximum sorting amount.
Someone should find the number of recursive sorts this algorithm must perform, and analyze a histogram of the sizes of those sorts. For N = 2^20, they are in sort/quicksorter-220sorts.txt.gz.
This program is not artificially dumb--for instance, it doesn't stupidly perform a random swap before checking n <= 1--but it is not as good as it should be.
Suppose before we add to this algorithm, we optimize it. For instance, a person notices that one half of the recursive function calls are for N = 0. In fact, for both this case and the case N = 1, the function call is an entire wasted sort. Furthermore, the recursively-used sort function needlessly evaluates n <= 1. Certainly on its own it can guarantee that both cases will not occur.
Before submitting real sorts to the true sorting function, a wrapper sort function can reply immediately to "phone calls" asking for ridiculous sorts like that; ideally, a sort function would not allow them at all. This idea further allows one to name the real sort functions uniquely, with whatever makes them special, and use "sort" only for the generic interface symbol.
Also, one notices things like sort(a+k+1, z-k-1), which performs an addition and subtraction by one, when k++ could be placed first, to eliminate them. No matter how small, not making an optimization like that is bad style, if it isn't worse. (In the optimized version, there are actually two subtractions and one addition saved, at the cost of one addition.)
/* libquicksort1.c */
#include "libsort.h"
void swap(c *a, c *b) {
c t;
t = *a;
*a = *b;
*b = t;
}
void quicksort(c *a, int z) {
int i, k;
swap(a, a+rand()%z);
for (i=1,k=0; i<z; i++)
if (a[i] < *a)
swap(a+i, a+ ++k);
swap(a, a+k);
if (k > 1)
quicksort(a, k);
k++;
if (z-k > 1)
quicksort(a+k, z-k);
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
We'll stop with those simple optimizations, noting that they increase performance four-fold. Other ones could be performed, but without changing the architecture of the program, which is what we are about to do, they do not have any profit.
One example of that is to eliminate swaps with the same element--but if no other benefit is gained, the expected profit is extremely small. (It is to be assumed that optimizations such as assigning t = *a, and using if (a[i] < t) will be automatically performed.)
Half as many recursive calls are necessary. See sort/quicksorter1-220sorts.txt.gz.
Now it's time that we need a regulated testing mechanism. One should be able to instantly test each change, and later on, one should also be able to instantly see performance differences. Of the two, performance tests may be too slow, and early ones tolerable for partially developed programs might not apply to the large capacity and speed obtained before the final solution is concluded.
It is sufficient to test a general sorting algorithm (depending on how many levels of convergence occur before it recurses) with all permutations of N = 3 or 5. But this isn't enough to test the program. Full input for all bytes or strings, must be randomly tested in somewhat large amounts--e.g., 100,000 bytes on [0,255].
Enacting rd 100000 < /dev/random > 100000, and producing its sort, will provide this.
Thereafter, here is a test suite:
# test.sh perms="12345 12354 12453 12435 12534 12543 13452 13425 13524 13542 13245 13254 14523 14532 14235 14253 14352 14325 15234 15243 15342 15324 15423 15432 23451 23415 23514 23541 23145 23154 24513 24531 24135 24153 24351 24315 25134 25143 25341 25314 25413 25431 21345 21354 21453 21435 21534 21543 34512 34521 34125 34152 34251 34215 35124 35142 35241 35214 35412 35421 31245 31254 31452 31425 31524 31542 32451 32415 32514 32541 32145 32154 45123 45132 45231 45213 45312 45321 41235 41253 41352 41325 41523 41532 42351 42315 42513 42531 42135 42153 43512 43521 43125 43152 43251 43215 51234 51243 51342 51324 51423 51432 52341 52314 52413 52431 52134 52143 53412 53421 53124 53142 53241 53214 54123 54132 54231 54213 54312 54321" for a in $perms; do b=`echo -n $a | ./$1` if test $? != 0 || test $b != 12345 then echo ./$a: failure $a exit fi done ./$1 < 100000 | cmp - 100000.sort
Refinements
If data is given to quicksort in backwards order, it runs to N^2. Nothing but one movement closer to sorted order can be accomplished in each recursion.
However, since backwards data really is in sorted order, we may with little work change it to forwards order. In fact, since we expect a chance approaching 1/2 that the last value is less than the first, we incur no loss in general progress towards sorting (although it may turn out to be very hard to find a way of utilizing any such progress within the cryptic quicksort algorithm).
By being careful, we can also make certain other guarantees about the order of data that has been processed, which will aid in future refinements. In every case, it is nice to know--and essential to know--the properties of the result of every operation which your program performs.
/* libquicksort2.c */
#include "libsort.h"
void swap(c *a, c *b) {
c t;
t = *a;
*a = *b;
*b = t;
}
void quicksort(c *a, int z) {
c t;
int i, k, l;
for (i=0,l=z-1; a[i]>a[l];) {
t = a[l];
a[l] = a[i];
a[i] = t;
if (i == l-1)
return;
if (a[i+1] < t)
break;
i++;
if (a[l-1] > a[l])
break;
l--;
if (a[l] < t)
break;
if (a[i] > a[l+1])
break;
/* Strictly speaking, I have a style
that a single condition in if need not be
upon a line by itself, but now I vary. */
}
swap(a, a+rand()%z);
for (i=1,k=0; i<z; i++)
if (a[i] < *a)
swap(a+i, a+ ++k);
swap(a, a+k);
if (k > 1)
quicksort(a, k);
k++;
if (z-k > 1)
quicksort(a+k, z-k);
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
Starting with this one, a table may be present below the cut-out of an algorithm, to demonstrate some performance figures. N refers to the number of elements in the random dataset, and the following columns each refer to the mean of the sort times in milliseconds for that program. The number of significant figures shown is approximately correct, plus one estimated.
| N | quicksorter | quicksorter1 | quicksorter2 |
|---|---|---|---|
| 2 | 0.000763 | 0.000458 | 0.000305 |
| 4 | 0.001221 | 0.000916 | 0.000763 |
| 5 | 0.001144 | 0.000954 | 0.001335 |
| 8 | 0.002136 | 0.001831 | 0.002136 |
| 11 | 0.002937 | 0.002518 | 0.002937 |
| 16 | 0.00488 | 0.00427 | 0.00427 |
| 22 | 0.00755 | 0.00587 | 0.00587 |
| 32 | 0.00977 | 0.00977 | 0.01099 |
| 45 | 0.01545 | 0.01373 | 0.01373 |
| 64 | 0.02197 | 0.02197 | 0.01953 |
| 90 | 0.0309 | 0.0343 | 0.0275 |
| 128 | 0.0439 | 0.0439 | 0.0488 |
| 181 | 0.0691 | 0.0760 | 0.0691 |
| 256 | 0.1074 | 0.0977 | 0.0977 |
| 362 | 0.1519 | 0.1519 | 0.1519 |
| 512 | 0.2344 | 0.2148 | 0.2148 |
| 724 | 0.331 | 0.304 | 0.304 |
| 1024 | 0.430 | 0.547 | 0.508 |
| 1448 | 0.829 | 0.663 | 0.773 |
| 2048 | 1.250 | 1.094 | 1.094 |
| 2896 | 1.667 | 1.556 | 1.667 |
| 4096 | 2.812 | 2.344 | 2.500 |
| 5792 | 4.00 | 3.78 | 3.78 |
| 8192 | 6.25 | 5.62 | 5.62 |
| 11585 | 10.91 | 9.09 | 10.45 |
| 16384 | 16.88 | 16.25 | 17.50 |
| 23170 | 30.00 | 25.45 | 30.00 |
| 32768 | 48.75 | 46.25 | 52.50 |
| 46340 | 88.0 | 80.0 | 98.0 |
| 65536 | 162.5 | 157.5 | 185.0 |
| 92681 | 300.0 | 290.0 | 345.0 |
| 131072 | 575.0 | 560.0 | 680.0 |
| 185363 | 1130.0 | 1120.0 | 1350.0 |
| 262144 | 2160.0 | 2140.0 | 2550.0 |
This second table shows the results for four special test cases. Times are likewise given in milliseconds for each program. First, ordered, is a test of pre-sorted data. Second, deredro, is perfectly backwards, pre-sorted data. Third, forwards.rp, is a repetition of the string abcdefghijklmnopqrstuvwxyz\n, and fourth, backwards.rp is a repetition of the string zyxwvutsrqponmlkjihgfedcba\n; both are repeated 9602 times.
(The output of both of the last cases, for instance, should be the same: \n(x9602), a(x9602), b(x9602), ..., z(x9602).)
| sorter | ordered | deredro | forwards.rp | backwards.rp |
|---|---|---|---|---|
| quicksorter | 8240 | 8240 | 18870 | 18720 |
| quicksorter1 | 8150 | 8210 | 18920 | 18870 |
| quicksorter2 | 9760 | 10 | 22630 | 22590 |
This is a very short step in making progress. However, we have nearly perfectly accomplished our goal in sorting strictly out-of-order data. The quicksort algorithm itself never need be used, anyway--why sort again, when the real work of sorting the data was already done? It means nothing that it was backwards to that the fact that it was sorted.
Now if data, working from each end, has been changed to forwards order, it is easy to see if the remainder in the middle is already in order. Regardless, sorting of in-order data is also N^2 with quicksort, so to finish the work we have begun, we need to advance through what is left in the middle until it is out of order.
We need to do this anyway, to take full advantage of what we have already done, because the reversal procedure will be just as slow as before on certain inputs of reversed elements (this is when the reversal process converges to equal values in the middle, and reversal stops, because the middle point remains in forwards order while the others are reversed).
Yet, at this point, let's analyze our guarantees, starting from where the basic quickstart algorithm now begins.
First, we know there exists an increasing sequence of one or more elements at the beginning of the data, as well as an increasing sequence of one or more elements at the end of the data. Without loss of generality, we know also that the last of the first sequence is less than or equal to the first of the second sequence.
Furthermore, what is critical, and what could not be improved upon without extended proofs and conditions, is that a[i] is a satisfactory supremum of the first sequence, and a[l] is a satisfactory infimum of the second. If we try to reach for anything more, we discover that there are pairs of elements which lurk together in such a manner as to require waste to establish anything--and this is only to have a 50% chance of any improvement, slowly by one element, and by another element.
Now we finally have the means with which to reduce a great deal more of the work.
/* libquicksort3.c */
#include "libsort.h"
void swap(c *a, c *b) {
c t;
t = *a;
*a = *b;
*b = t;
}
void quicksort(c *a, int z) {
c t;
int i, k, l;
for (i=0,l=z-1; a[i]>a[l];) {
t = a[l];
a[l] = a[i];
a[i] = t;
if (i == l-1)
return;
if (a[i+1] < t)
break;
i++;
if (a[l-1] > a[l])
break;
l--;
if (a[l] < t)
break;
if (a[i] > a[l+1])
break;
}
for (; i<l; i++)
if (a[i+1] < a[i])
break;
if (i == l)
return;
swap(a, a+rand()%z);
for (i=1,k=0; i<z; i++)
if (a[i] < *a)
swap(a+i, a+ ++k);
swap(a, a+k);
if (k > 1)
quicksort(a, k);
k++;
if (z-k > 1)
quicksort(a+k, z-k);
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
We've now surpassed the performance of qsort(3) on Unix, and we accomplish the sort of 2^20 random elements in about 628 minus 1 recursive sorts. See sort/quicksorter3-220sorts.txt.gz.
We can do better now. We don't need a random swap. That's the cheap way of using probability to find good partitions. We also can eliminate the i=1 from the quicksort loop, starting wherever i happens to be, and go only to l+1 instead of to z.
/* libquicksort4.c */
#include "libsort.h"
void swap(c *a, c *b) {
c t;
t = *a;
*a = *b;
*b = t;
}
void quicksort(c *a, int z) {
c t;
int i, k, l;
for (i=0,l=z-1; a[i]>a[l];) {
t = a[l];
a[l] = a[i];
a[i] = t;
if (i == l-1)
return;
if (a[i+1] < t)
break;
i++;
if (a[l-1] > a[l])
break;
l--;
if (a[l] < t)
break;
if (a[i] > a[l+1])
break;
}
for (; i<l; i++)
if (a[i+1] < a[i])
break;
if (i == l)
return;
/* This loop does absolutely nothing--it
never runs!--in fact, conditions from above
guarantee that it never will run; yet it
decreases running time consistently by
50 ms, 1/6th of the sorting time, on a
dataset of 1,000,000 elements, by its
presence. */
/*
for (; i<l; i++)
if (a[i] >= a[0]) break;
else printf("this never happens!\n");
*/
/* I would perhaps think that it forces
the compiler to realize that an optimization
is valid for the following loop, even though,
of course, that optimization by necessity
would be valid anyway. */
/* Instead, I found out that what I thought
was not true, and the compiler did not
fix *a from the following loop to a
temporary constant, so I did that, since I
had the extra variable already around.
Perhaps having two loops with that variable
changed the compiler's decision.
(Faint-hearted compiler--the compiler
should have made an optimization on
*a/a[0], as I said even in this same article:
"It is to be assumed that optimizations such
[as this]... will be automatically performed."
And so they should be--for style as well as
CPU.) */
t = *a;
/* Testing with both t = *a, etc., and the
loop mentioned previously showed no
improvement over t = *a by itself.
Apparently, this proves that this was the
exact optimization that the presence of the
above commented-out loop forced the compiler
to make. No one should have to try to
do what I did and penetrate through the
aura of a magical spell surrounding some
element of code which is functionless.
Compilers should be more reliable about
how they decide to make optimizations. */
for (k=0,l++; i<l; i++)
if (a[i] < t)
swap(a+i, a+ ++k);
/* Oh, my, pianoforte, plus-plus-k;
it's a test program, and I may write
comments, even about music on Radio Kansas;
shall I enter their contest? */
swap(a, a+k);
if (k > 1)
quicksort(a, k);
k++;
if (z-k > 1)
quicksort(a+k, z-k);
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
Now 807 minus 1 recursive sorts are required for 2^20 elements of random data, but it is better by 80 ms, or about 1/5th of the sorting time.
Now, almost the only thing we may be able to do is to use all of this information to deliberately choose a better partition in each sort; this might be impossible--to beat probability by very much is hard to do without analysis that may be at least as expensive.
But in the meantime, let's rewrite our other two algorithms, so we can go only to l, and so that we have cleaner, nicer behavior, and sharp, well-defined guarantees before the quicksort algorithm starts in.
What we do is to set up boundaries for the convergence of the elements. Given that P = {x,y} is a set, i+1 = min P, and l-1 = max P, we define P convergent if i+1 >= a[i] and l-1 <= a[l]. If P is convergent, we set a[i+1] to i+1 and a[l-1] to l-1, and continue with P = {x+1, y-1}.
We don't carry that process out in its truest sense, because it has a disadvantage for in-order data, and we have no general reason to expect that sets will continue to converge with intervening occurrences of regular and reversed elements.
/* libquicksort5.c */
#include "libsort.h"
void swap(c *a, c *b) {
c t;
t = *a;
*a = *b;
*b = t;
}
void quicksort(c *a, int z) {
c r, t;
int i, k, l, m;
l=z-1;
if (*a > a[l])
swap(a, a+l);
if (l == 1)
return;
i=1, l--;
while (a[i] > a[l]) {
t = a[l];
a[l] = a[i];
a[i] = t;
if (t < a[i-1] || a[l] > a[l+1])
break;
i++;
if (i == l)
return;
l--;
}
i--, l++;
for (; i<l; i++)
if (a[i+1] < a[i])
break;
if (i == l)
return;
t = *a;
for (k=0; i<l; i++)
if (a[i] < t)
swap(a+i, a+ ++k);
swap(a, a+k);
if (k > 1)
quicksort(a, k);
k++;
if (z-k > 1)
quicksort(a+k, z-k);
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
Now it only remains to choose a better pivot, which we only marginally can expect to provide gains. We also add a loop before each recursive function call, which helps prevent thrashing from equal values around the partition boundary.
/* libquicksort6.c */
#include "libsort.h"
/* the highway score */
void quicksort(c *a, int z) {
c r, t;
int i, k, l, m;
l=z-1, t=*a;
if (t > a[l]) {
*a = a[l];
a[l] = t;
}
if (l == 1)
return;
i=1, l--;
while (a[i] > a[l]) {
t = a[l];
a[l] = a[i];
a[i] = t;
if (t < a[i-1] || a[l] > a[l+1])
break;
i++;
if (i == l)
return;
l--;
}
i--, l++;
m=i, t=a[i];
for (; i<l; i++)
if (a[i+1] < a[i])
break;
if (i == l)
return;
for (; l>i; l--)
if (a[l-1] > a[l] || a[l-1] < t)
break;
for (; m<i; m++)
if (a[m+1] > a[l])
break;
k = m, t = a[m];
if (m == i) {
for (; a[++i]<t; k++)
;
}
for (; i<l; i++)
if (a[i] < t) {
r = a[++k];
a[k] = a[i];
a[i] = r;
}
r = a[k];
a[k] = a[m];
a[m] = r;
m = k;
/* this loop doesn't do much,
except at the end of a sort */
for (; k>0; k--)
if (a[k-1] != t)
break;
if (k > 1) {
quicksort(a, k);
}
k = m+1;
for (; k<z; k++)
if (a[k] != t)
break;
if (z-k > 1)
quicksort(a+k, z-k);
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
Doing this allows us for the first time to accomplish a sort of 10*2^20 items in 2.98 seconds, and for 2^20 items, we complete our sort in 491 minus 1 recursive calls.
For reference, here's a nested list of the sorting operations for 10*2^20 elements randomly generated.
Sorting 10*2^20 items.Finally, we eliminate a significant amount of recursive function calls, a non-abstract optimization step that is appropriate to perform at the finalization of a program.
/* libquicksort7.c */
#include "libsort.h"
void quicksort(c *a, int z) {
c r, t;
int i, k, l, m;
J:
l=z-1, t=*a;
if (t > a[l]) {
*a = a[l];
a[l] = t;
}
if (l == 1)
return;
i=1, l--;
while (a[i] > a[l]) {
t = a[l];
a[l] = a[i];
a[i] = t;
if (t < a[i-1] || a[l] > a[l+1])
break;
i++;
if (i == l)
return;
l--;
}
i--, l++;
m=i, t=a[i];
for (; i<l; i++)
if (a[i+1] < a[i])
break;
if (i == l)
return;
for (; l>i; l--)
if (a[l-1] > a[l] || a[l-1] < t)
break;
for (; m<i; m++)
if (a[m+1] > a[l])
break;
k = m, t = a[m];
if (m == i) {
for (; a[++i]<t; k++)
;
}
for (; i<l; i++)
if (a[i] < t) {
r = a[++k];
a[k] = a[i];
a[i] = r;
}
r = a[k];
a[k] = a[m];
a[m] = r;
m = k;
for (; k>0; k--)
if (a[k-1] != t)
break;
if (k > 1) {
quicksort(a, k);
}
k = m+1;
for (; k<z; k++)
if (a[k] != t)
break;
if (z-k > 1) {
a += k;
z -= k;
goto J;
}
}
void sort(c *a, int z) {
if (z <= 1)
return;
quicksort(a, z);
}
For sorting the first sample taken of 2,097,152 random items, there are now only 257 minus 1 recursive function calls. (The time is 0.560 seconds.)
function calls by order and size call stackHere is our test program:
# sortperf.sh
cat <<EOF > /dev/null
Comments about testing
We have a file 'want' in . containing max (about 2^20)
random bytes. Sorting < 2^15 bytes or so takes an
extremely small amount of time. To test the sort time
accurately, we have to account for deviation and time of
the executable itself--so we want the sorting to be
running > .9 of the time. The number of repetitions we
need to sort the input to obtain this depends on the
base rate (cpu speed, etc.) that any sort using the
algorithm will take.
Choose a max sort which takes about 1 second to run, so
that about 90% of the time for that is spent on the
sort.
Then for each sort that we time from the beginning up to
max, we'll take max / length of this sort as an approx n
of iterations. We expect running time to slightly
increase until it reaches 1 second as the test size goes
up.
This increase should be log n or so. If 1024 units take
10, then 2048 will take 11 time.
Of course, there are some K expenses, which we try to
get rid of by this whole procedure of repetition, and
some O(n) expenses from things like copying the original
input before each sort, but those divide out, so it
should still be log n. If it is n, then by indication
the sort is really an n^2 algorithm.
The sorting program that tests the sort has this kind of
an interface:
No arguments = sort stdin and print on stdout.
0 arg = sort stdin and print nothing
N arg = read <= N on stdin and do int(max*/N) sorts.
other = undefined
(*The value of max must be compiled in. This script
copies the value which is in sorter.h, so it assumes
that the program tested has been compiled after the most
recent modification of that header file.)
sorter.c is a program that does this. The sort function
with an interface as given in sorter.h should be in
another file and compiled into foosort.o, for instance.
cc foosort.o sorter.c -o foosorter will link that
together.
EOF
eval `grep MAX sorter.h | tr A-Z a-z | sed 's| ||g'`
for a in `perl -e \
"for (3..int(log($max+1)/log(sqrt(2))))
{ print int(2**(\\$_/2)), ' ' }"`
do
echo $a `sh timer.sh $1 $a want $max`
done
Here is a library for testing qsort(3):
/* libqsort.c */
#include "libsort.h"
int ncmp(const void *a, const void *b) {
return * (c *) a - * (c *) b;
}
void sort(c *a, int n) {
qsort(a, n, 1, ncmp);
}
Here results for quicksorter3 through quicksorter6, and for qsorter, are given in a table.
| N | qsorter | quicksorter3 | quicksorter4 | quicksorter5 | quicksorter6 |
|---|---|---|---|---|---|
| 2 | 0.00041199 | 0.00020027 | 0.00020599 | 0.00019455 | 0.00019646 |
| 4 | 0.00069427 | 0.00080109 | 0.00051880 | 0.00048828 | 0.00050354 |
| 5 | 0.00095367 | 0.00103951 | 0.00077724 | 0.00073910 | 0.00073433 |
| 8 | 0.00170898 | 0.00167847 | 0.00112915 | 0.00080872 | 0.00103760 |
| 11 | 0.0027590 | 0.0024128 | 0.0015211 | 0.0014372 | 0.0017834 |
| 16 | 0.0045319 | 0.0037842 | 0.0024872 | 0.0027008 | 0.0034637 |
| 22 | 0.0053291 | 0.0056438 | 0.0033150 | 0.0031471 | 0.0039864 |
| 32 | 0.0091858 | 0.0088806 | 0.0051880 | 0.0049744 | 0.0058899 |
| 45 | 0.0140334 | 0.0130463 | 0.0074673 | 0.0073386 | 0.0100851 |
| 64 | 0.0211792 | 0.0193481 | 0.0119629 | 0.0112305 | 0.0140991 |
| 90 | 0.032787 | 0.028324 | 0.017681 | 0.017681 | 0.020857 |
| 128 | 0.047119 | 0.042603 | 0.026489 | 0.026611 | 0.030151 |
| 181 | 0.071118 | 0.062487 | 0.039874 | 0.039184 | 0.044880 |
| 256 | 0.103027 | 0.089844 | 0.057129 | 0.059326 | 0.065430 |
| 362 | 0.152247 | 0.132914 | 0.089760 | 0.088379 | 0.097356 |
| 512 | 0.21045 | 0.19141 | 0.12354 | 0.12354 | 0.13379 |
| 724 | 0.29690 | 0.27480 | 0.18435 | 0.18435 | 0.20300 |
| 1024 | 0.42871 | 0.38574 | 0.27734 | 0.27539 | 0.29492 |
| 1448 | 0.60075 | 0.53169 | 0.37702 | 0.39635 | 0.39912 |
| 2048 | 0.83984 | 0.72266 | 0.53320 | 0.52148 | 0.52734 |
| 2896 | 1.18232 | 0.97790 | 0.67680 | 0.69337 | 0.74033 |
| 4096 | 1.6602 | 1.3438 | 0.9883 | 1.0156 | 1.0078 |
| 5792 | 2.2431 | 1.8287 | 1.3646 | 1.4144 | 1.2873 |
| 8192 | 3.2031 | 2.5859 | 2.0156 | 1.9609 | 1.7734 |
| 11585 | 4.5525 | 3.5691 | 2.6630 | 2.5856 | 2.6188 |
| 16384 | 6.3594 | 5.0312 | 3.8594 | 3.7969 | 3.6562 |
| 23170 | 9.0487 | 7.1018 | 5.4867 | 5.4867 | 5.3319 |
| 32768 | 12.656 | 10.094 | 7.375 | 7.344 | 7.344 |
| 46340 | 17.743 | 14.381 | 10.619 | 10.752 | 10.575 |
| 65536 | 24.938 | 20.438 | 15.438 | 14.750 | 14.188 |
| 92681 | 36.549 | 29.115 | 21.593 | 22.035 | 20.177 |
| 131072 | 50.250 | 41.375 | 32.000 | 31.375 | 31.000 |
| 185363 | 73.750 | 58.571 | 45.179 | 44.286 | 44.286 |
| 262144 | 107.25 | 85.50 | 63.75 | 64.50 | 64.75 |
| 370727 | 146.07 | 122.86 | 91.07 | 89.64 | 92.50 |
| 524288 | 216.50 | 174.00 | 131.00 | 135.50 | 131.00 |
| 741455 | 295.71 | 246.43 | 198.57 | 195.71 | 189.29 |
| 1048576 | 423.00 | 360.00 | 272.00 | 275.00 | 272.00 |
| 1482910 | 612.9 | 514.3 | 381.4 | 384.3 | 378.6 |
| 2097152 | 866.0 | 746.0 | 572.0 | 588.0 | 548.0 |
| 2965820 | 1216.7 | 1053.3 | 786.7 | 823.3 | 790.0 |
| 4194304 | 1720.0 | 1490.0 | 1120.0 | 1190.0 | 1130.0 |
| 5931641 | 2520.0 | 2190.0 | 1650.0 | 1660.0 | 1610.0 |
| 8388608 | 3370.0 | 2930.0 | 2390.0 | 2510.0 | 2270.0 |
Here is the second table of special test cases. This time, ordered and deredro are 2^20 elements each, and forwards.rp and backwards.rp have lines of the lower case English alphabet repeated 37,037 times.
| sorter | ordered | deredro | forwards.rp | backwards.rp |
|---|---|---|---|---|
| qsorter | 310 | 320 | 250 | 260 |
| quicksorter3 | 30 | 40 | 230 | 240 |
| quicksorter4 | 20 | 40 | 190 | 210 |
| quicksorter5 | 20 | 20 | 180 | 190 |
| quicksorter6 | 20 | 30 | 170 | 190 |
Here is a second library for testing qsort, without the unnecessary comparision function used. After this raw implementation of the function from the FreeBSD C library is presented, there will be another table of results including the seventh version of sort and this version of qsort.
/*-
* Copyright (c) 1992, 1993
* The Regents of the University of California. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* 3. All advertising materials mentioning features or use of this software
* must display the following acknowledgement:
* This product includes software developed by the University of
* California, Berkeley and its contributors.
* 4. Neither the name of the University nor the names of its contributors
* may be used to endorse or promote products derived from this software
* without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE
* FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
* DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
* OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
* HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
* LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
* OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
* SUCH DAMAGE.
*/
#if defined(LIBC_SCCS) && !defined(lint)
static char sccsid[] = "@(#)qsort.c 8.1 (Berkeley) 6/4/93";
#endif /* LIBC_SCCS and not lint */
#include <sys/types.h>
// #include <stdlib.h>
#ifndef __
# ifdef __STDC__
# define __(x) x
# else
# define __(x) ()
# endif
#endif
static inline char *med3 __((char *, char *, char *));
static inline void swapfunc __((char *, char *, int, int));
#define min(a, b) (a) < (b) ? a : b
#define cmp(a, b) (* (unsigned char *) (a) - * (unsigned char *) (b))
/*
* Qsort routine from Bentley & McIlroy's "Engineering a Sort Function".
*/
#define swapcode(TYPE, parmi, parmj, n) { \
long i = (n) / sizeof (TYPE); \
register TYPE *pi = (TYPE *) (parmi); \
register TYPE *pj = (TYPE *) (parmj); \
do { \
register TYPE t = *pi; \
*pi++ = *pj; \
*pj++ = t; \
} while (--i > 0); \
}
#define SWAPINIT(a, es) swaptype = ((char *)a - (char *)0) % sizeof(long) || \
es % sizeof(long) ? 2 : es == sizeof(long)? 0 : 1;
static inline void
swapfunc(a, b, n, swaptype)
char *a, *b;
int n, swaptype;
{
if(swaptype <= 1)
swapcode(long, a, b, n)
else
swapcode(char, a, b, n)
}
#define swap(a, b) \
if (swaptype == 0) { \
long t = *(long *)(a); \
*(long *)(a) = *(long *)(b); \
*(long *)(b) = t; \
} else \
swapfunc(a, b, es, swaptype)
#define vecswap(a, b, n) if ((n) > 0) swapfunc(a, b, n, swaptype)
static inline char *
med3(a, b, c)
char *a, *b, *c;
{
return cmp(a, b) < 0 ?
(cmp(b, c) < 0 ? b : (cmp(a, c) < 0 ? c : a ))
:(cmp(b, c) > 0 ? b : (cmp(a, c) < 0 ? a : c ));
}
void
qsort2(a, n)
char *a;
size_t n;
{
char *pa, *pb, *pc, *pd, *pl, *pm, *pn;
int d, r, swaptype, swap_cnt;
size_t es = 1;
loop: SWAPINIT(a, es);
swap_cnt = 0;
if (n < 7) {
for (pm = a + es; pm < (char *) a + n * es; pm += es)
for (pl = pm; pl > (char *) a && cmp(pl - es, pl) > 0;
pl -= es)
swap(pl, pl - es);
return;
}
pm = a + (n / 2) * es;
if (n > 7) {
pl = a;
pn = a + (n - 1) * es;
if (n > 40) {
d = (n / 8) * es;
pl = med3(pl, pl + d, pl + 2 * d);
pm = med3(pm - d, pm, pm + d);
pn = med3(pn - 2 * d, pn - d, pn);
}
pm = med3(pl, pm, pn);
}
swap(a, pm);
pa = pb = a + es;
pc = pd = a + (n - 1) * es;
for (;;) {
while (pb <= pc && (r = cmp(pb, a)) <= 0) {
if (r == 0) {
swap_cnt = 1;
swap(pa, pb);
pa += es;
}
pb += es;
}
while (pb <= pc && (r = cmp(pc, a)) >= 0) {
if (r == 0) {
swap_cnt = 1;
swap(pc, pd);
pd -= es;
}
pc -= es;
}
if (pb > pc)
break;
swap(pb, pc);
swap_cnt = 1;
pb += es;
pc -= es;
}
if (swap_cnt == 0) { /* Switch to insertion sort */
for (pm = a + es; pm < (char *) a + n * es; pm += es)
for (pl = pm; pl > (char *) a && cmp(pl - es, pl) > 0;
pl -= es)
swap(pl, pl - es);
return;
}
pn = a + n * es;
r = min(pa - (char *)a, pb - pa);
vecswap(a, pb - r, r);
r = min(pd - pc, pn - pd - es);
vecswap(pb, pn - r, r);
if ((r = pb - pa) > es)
qsort2(a, r / es);
if ((r = pd - pc) > es) {
/* Iterate rather than recurse to save stack space */
a = pn - r;
n = r / es;
goto loop;
}
/* qsort2(pn - r, r / es, es);*/
}
void sort(char *a, int n) {
if (n > 1)
qsort2(a, n);
}
| N | qsort-freebsd-modifieder | qsorter | quicksorter3 | quicksorter4 | quicksorter5 | quicksorter6 | quicksorter7 |
|---|---|---|---|---|---|---|---|
| 2 | 0.000256538 | 0.00041866 | 0.000213623 | 0.000217438 | 0.000203133 | 0.000209808 | 0.000205994 |
| 4 | 0.00047112 | 0.00076294 | 0.00029945 | 0.00029945 | 0.00030136 | 0.00031281 | 0.00030708 |
| 5 | 0.00059366 | 0.00093699 | 0.00099897 | 0.00057459 | 0.00048876 | 0.00063419 | 0.00060797 |
| 8 | 0.00104141 | 0.0018158 | 0.0017204 | 0.00106430 | 0.00097275 | 0.00117111 | 0.00115204 |
| 11 | 0.00137949 | 0.0022922 | 0.0024705 | 0.0014372 | 0.0016942 | 0.0015945 | 0.0015736 |
| 16 | 0.0030060 | 0.0054092 | 0.0038528 | 0.0024109 | 0.0023575 | 0.0027390 | 0.0027618 |
| 22 | 0.0034304 | 0.0058117 | 0.0056648 | 0.0033779 | 0.0033884 | 0.0040073 | 0.0039969 |
| 32 | 0.0056458 | 0.009506 | 0.008636 | 0.0054932 | 0.0052490 | 0.0066986 | 0.0065918 |
| 45 | 0.008047 | 0.013583 | 0.012767 | 0.008390 | 0.008519 | 0.009828 | 0.009763 |
| 64 | 0.012695 | 0.021484 | 0.019135 | 0.011505 | 0.012207 | 0.014679 | 0.014740 |
| 90 | 0.020084 | 0.033088 | 0.027895 | 0.017810 | 0.018368 | 0.021243 | 0.021029 |
| 128 | 0.029541 | 0.04810 | 0.04108 | 0.027100 | 0.028076 | 0.030518 | 0.030029 |
| 181 | 0.04272 | 0.07138 | 0.06067 | 0.04056 | 0.04013 | 0.04393 | 0.04410 |
| 256 | 0.06470 | 0.10608 | 0.08801 | 0.06116 | 0.06152 | 0.06775 | 0.06750 |
| 362 | 0.09304 | 0.15294 | 0.12894 | 0.08890 | 0.08683 | 0.09597 | 0.09546 |
| 512 | 0.13110 | 0.2148 | 0.18335 | 0.14062 | 0.13745 | 0.13794 | 0.13916 |
| 724 | 0.1861 | 0.3004 | 0.2627 | 0.1816 | 0.1850 | 0.1985 | 0.1957 |
| 1024 | 0.2627 | 0.4224 | 0.3735 | 0.2690 | 0.2676 | 0.2832 | 0.2764 |
| 1448 | 0.3970 | 0.6276 | 0.5109 | 0.3956 | 0.4019 | 0.3949 | 0.3915 |
| 2048 | 0.5576 | 0.8652 | 0.6924 | 0.5342 | 0.5527 | 0.5371 | 0.5312 |
| 2896 | 0.7789 | 1.175 | 0.925 | 0.6947 | 0.7140 | 0.7375 | 0.7292 |
| 4096 | 1.090 | 1.648 | 1.271 | 1.064 | 1.070 | 1.080 | 1.078 |
| 5792 | 1.528 | 2.262 | 1.729 | 1.367 | 1.403 | 1.304 | 1.315 |
| 8192 | 2.074 | 3.117 | 2.422 | 1.895 | 1.902 | 1.863 | 1.867 |
| 11585 | 2.972 | 4.39 | 3.381 | 2.646 | 2.630 | 2.724 | 2.702 |
| 16384 | 4.24 | 6.24 | 4.70 | 3.72 | 3.86 | 3.71 | 3.68 |
| 23170 | 6.11 | 8.85 | 6.72 | 5.36 | 5.49 | 5.27 | 5.30 |
| 32768 | 8.59 | 12.34 | 9.55 | 7.55 | 7.67 | 7.36 | 7.34 |
| 46340 | 12.21 | 17.50 | 13.41 | 11.13 | 10.82 | 10.71 | 10.73 |
| 65536 | 17.69 | 25.5 | 19.1 | 16.06 | 15.88 | 15.91 | 15.56 |
| 92681 | 24.5 | 35.2 | 27.6 | 24.6 | 22.5 | 22.2 | 21.9 |
| 131072 | 34.8 | 49.7 | 38.9 | 30.8 | 31.8 | 30.2 | 29.9 |
| 185363 | 48.6 | 70.7 | 56.6 | 47.5 | 46.5 | 45.5 | 45.0 |
| 262144 | 73.2 | 103 | 78.9 | 69.6 | 68.4 | 64.5 | 63.1 |
| 370727 | 103 | 147 | 115 | 98 | 96 | 93 | 93 |
| 524288 | 150 | 211 | 166 | 137 | 142 | 135 | 135 |
| 741455 | 215 | 306 | 238 | 201 | 201 | 196 | 195 |
| 1048576 | 298 | 431 | 346 | 278 | 279 | 270 | 270 |
| 1482910 | 420 | 611 | 491 | 410 | 410 | 400 | 400 |
| 2097152 | 590 | 870 | 730 | 580 | 580 | 560 | 560 |
| 2965820 | 850 | 1221 | 1061 | 871 | 901 | 850 | 831 |
| 4194304 | 1190 | 1760 | 1430 | 1230 | 1260 | 1220 | 1220 |
| 5931641 | 1700 | 2500 | 1900 | 1701 | 1800 | 1641 | 1660 |
| 8388608 | 2500 | 3600 | 3000 | 2500 | 2500 | 2400 | 2400 |
| 11863283 | 3700 | 5200 | 4400 | 3800 | 3800 | 3600 | 3600 |
| 16777216 | 5100 | 7200 | 5900 | 5100 | 5400 | 5000 | 5000 |
| sorter | ordered | deredro | forwards.rp | backwards.rp |
|---|---|---|---|---|
| qsorter | 310 | 330 | 250 | 270 |
| qsort-freebsd-modifieder | 220 | 230 | 170 | 180 |
| quicksorter3 | 30 | 40 | 230 | 180 |
| quicksorter4 | 10 | 40 | 150 | 190 |
| quicksorter5 | 20 | 30 | 170 | 190 |
| quicksorter6 | 20 | 30 | 200 | 170 |
| quicksorter7 | 20 | 20 | 190 | 160 |
Here is a program to produce graphs and tables for all of the sorting programs:
# reports.sh
# for all tests
quicksorts="`echo quicksorter{,1,2,3,4,5,6,7}`"
qsort="qsorter qsort-freebsd-modifieder"
# for fast tests
quicksorts="`echo quicksorter{3,4,5,6,7}`"
qsort="qsorter qsort-freebsd-modifieder"
eval `grep extras= perfsetup.sh`
eval `grep eval sortperf.sh | grep MAX`
if test $1 -a -d $1; then
echo $0 start date
date
echo '--- %' > $1/extras.1
echo sorter $extras >> $1/extras.1
echo -n "set terminal png; plot x*log(x)/20000" \
> $1/plot.in
for a in $qsort $quicksorts; do
echo $a
sh sortperf.sh $a | tee $1/$a.dat
perl log.pl < $1/$a.dat > $1/$a.refine
echo -n ", '$a.dat'" >> $1/plot.in
echo -n $a >> $1/extras.1
for b in $extras
do
echo -n '' `sh timer.sh $a 0 $b` | tee -a $1/extras.1
done
echo >> $1/extras.1
done
(cd $1;
sed "s|dat'|refine'|g" < plot.in | sed 's|x\*log(x)/20000,||' > plot2.in;
gnuplot < plot.in > plot.png;
gnuplot < plot2.in > plot2.png;
echo -- >> extras.1;
~/bin/tbl f < extras.1 | perl ~/bin/thtml > extras.html)
echo $0 end date
date
else
echo usage: $0 dir
echo creates reports in dir
fi
And here's a setup script:
# perfsetup.sh
eval `grep eval sortperf.sh | grep MAX`
rd $max < /dev/random > want
rm *.o
eval `grep quicksorts= reports.sh`
eval `grep qsort= reports.sh`
for a in $quicksorts $qsort; do
sh $a.sh
done
extras="ordered deredro forwards.rp backwards.rp"
perl -e \
'for (0..255) { print chr($_)x4096; }' \
> ordered
perl -e \
'for (0..255) { print chr(255-$_)x4096; }' \
> deredro
echo abcdefghijklmnopqrstuvwxyz \
| rp 37037 > forwards.rp
echo zyxwvutsrqponmlkjihgfedcba \
| rp 37037 > backwards.rp
x=`expr $max / 4096`; x=`expr $x \* 4096`
y=`expr $max / 37037`; y=`expr $y \* 37037`
for a in ordered deredro; do
rd $x < $a > o.$$
mv o.$$ $a
done
for a in {for,back}wards.rp; do
rd $y < $a > o.$$
mv o.$$ $a
done
So we just have to change sorter.h, and run, for example:
sh perfsetup.sh mkdir testresults sh reports.sh testresults
We compile every program with -O3 -funroll-loops.
The first three revisions of our program can't well go beyond the value of max = 262144 or so, and still have any reasonable comparison. This value makes our first graph.
It's called Variations and Fugue on a theme by Handel. (The variations are by Brahams, and the Fugue.)
The y-axis is in ms, and the x-axis shows elements in the random sorting set.
We believe that 20,000 basic elements per ms is the constant cost of a sort, so we accompany the graph by the graph of (n log n) / 20000.
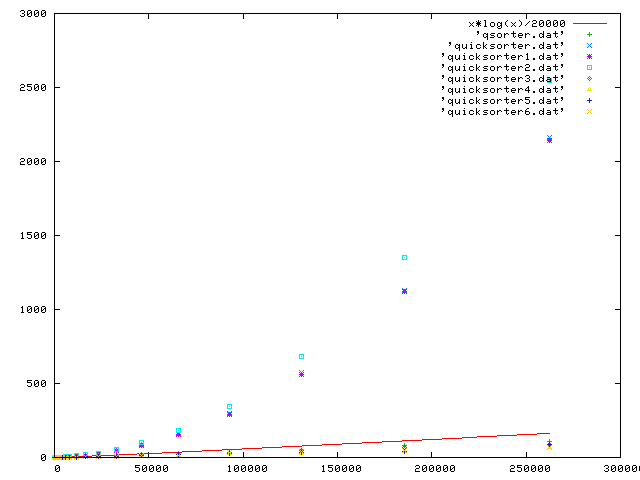
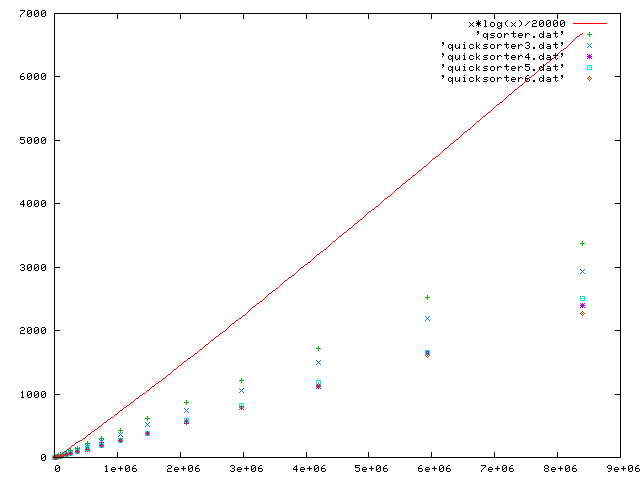
The second plot shows only the more refined programs. (Although quicksort is theoretically an n log n algorithm, it is not so under some poor implementations.)
Finally, we make this last graph using a neat mathematical trick. The theoretical bound of general sort performance on n elements is a constant times n log n. If an algorithm performs according to K plus a constant multiple of n log n, then there is a way of checking this property for each plot from the first graph of all the sorting programs.
Replacing each y(n) from the dataset with y(n) / (n log n) should converge to a constant, and produce a horizontal line. Why? If y(n) = K (n log n), then y(n) / (n log n) = K (n log n) / (n log n) = K. Regardless of the value of K, the result should converge to K, and the graph of y(n) / (n log n) should have an approximate slope of 0. On the other hand, if the algorithm behaves as N^2, then its transformed graph behaves as K n^2 / (n log n) = K n / log n.
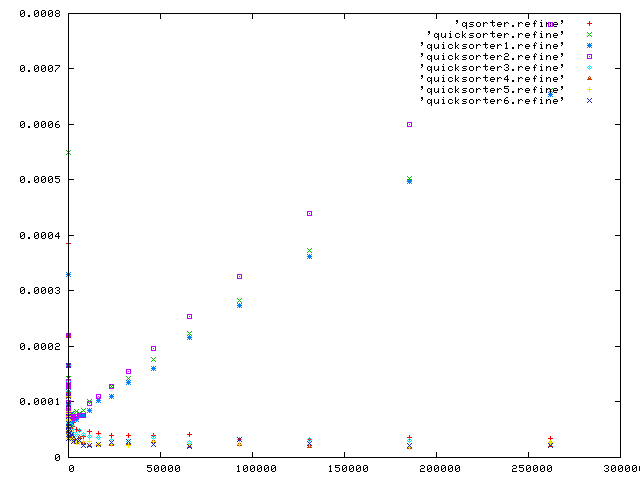
All testing was done on a 333 MHz processor.
http://www.myersdaily.org/joseph/unix/sort.txt