Saturday, July 17, 2004
In 1999, a long time ago by today's standards, which regard today as the only glass envelope worth having open, though even tomorrow will be yesterday soon, one could see StuffIt on a Macintosh encode and decode attachments and other files into MIME/Base64 format. An interested spectator would have noticed that the encoding rate was 600 KB/sec on a 333 MHz computer (800 KB/sec of output).
If one learned to program, one might write a program like this.
/* Base64.c */
#include <math.h>
#include <stdio.h>
const char b64_chars[65] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int main(void) {
int triplet, quartet, i, t;
char buffer[3];
while (t = fread(buffer, 1, 3, stdin)) {
triplet = 0;
for (i=0; i<t; i++) {
triplet += buffer[i] * pow(256, i);
}
for (i=0; i<4; i++) {
printf("%c", i<=t ? b64_chars[triplet%64] : '=');
triplet /= 64;
}
}
return 0;
}
Never mind that it doesn't produce real Base64 output. The format which it does produce can still be decoded, by another program like it.
The speed of it is 1,000,000 bytes in 2.05 computing seconds on the processor. A compiler can optimize that to more--about 0.55 seconds--so there is a top speed of 1,800 KB/sec. We're really glad, because test implementations at first could only be optimized up to 600 KB/sec, the same speed as the only reference that we know of--a great program from Aladdin software (for all we know now).
But look, that's nice, isn't it? Base64 is a nice, clear sounding name. It's the more than the same speed as other software.
Someone might even play around with that program, and be amazed at the blinding speed-of-light speed of fread() compared to read(). We don't even have to understand that the real functions are indeed read() and write(), and that fread() is faster because secretly behind us, it eliminates the problems caused by doing what we should never be doing--reading and writing all of our input and output in groups of only 3 and 4 characters at a time.
So we're now really, really satisfied with our program. We can actually find ways of making it run slower, so that proves to our thinking that it must really be the fastest, most optimized program.
Yet, how do we know that our reference program is good? We aren't satisfied just by beating what we know about.
So we play around later on, thinking about neater ways of doing it, and it still bothers us after a few years that our "Base64" encoding really is not (and so our program is useless--except for useless things, that is, like playing with it on our own computer).
We come up with this. It's a great program:
/* b64.c */
#include <stdio.h>
const char c64[65] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
int main(void) {
unsigned int b=0, c, l=0;
while ((c=getchar()) != EOF) {
b = (b<<8) + c;
l += 8;
while (l >= 6)
putchar(c64[(b>>(l-=6))%64]);
}
if (l > 0)
putchar(c64[((b%16)<<(6-l))%64]);
if (l != 0) while (l < 6)
putchar('='), l += 2;
return 0;
}
We've finally realized that doing transcendent math for three values that have to be recalculated over and over again for each iteration is not a good idea.
It reaches 0.360 seconds for encoding 1,000,000 bytes of input, unoptimized. Optimized, it is down to 0.110, 0.120, or, on one lucky trial of our miss-or-match operating system, a stated time of 0.070 seconds. (By now we are forgetting that the milliseconds on our computer are always insignificant values, because CLOCKS_PER_SEC is only 100, but we don't even know about that yet. And if we did know about it, we'd probably come to even more absurd results. We're far, far below the point of realizing that even functions like clock() are worse than stupid.)
Finally, we decide to have a standard quoted time of 0.790 seconds for 10,000,000 bytes. (We don't have real testing and regression mechanisms yet, so it's easier for us to use powers of 10 values.)
So far we've learned how to make beautifully reduced work. We've learned to be like old idiots who used to be smart programmers, and who now use abstract functions like getchar() and putchar(), and who say that memmove() should be used instead of memcpy(). Our programming is at the middle point of its premature life cycle. (At one point, we learned about registers, and wrote all our programs with "register char, register int," etc., but now we realize that optimizers do that, and so we even know something about programming style vs. ignorance.)
And this nice name, b64, is such an advancement. We've finally learned that Base64 is not even a feature--it is so inconvenient to type such a long, capitalized name.
And who knows? Maybe we've even learned about optimizations.
Except, it comes to pass that one day we see a dumb little Perl module: called MIME::Base64. Inside of it is some code from XXX or other programmer, that we say "inspires" us.
So we copy the code, make a neat little variation to match up with our name, bff, for the decoding program, and call our encoding program b63. (Except we don't realize that if we mean bff to represent base 256, then base 64 is 3f.)
/* base-63.h */
const unsigned char c63[65] =
"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
unsigned char l63[256];
void Al63() {
int i;
for (i=0; i<64; i++)
l63[c63[i]] = i;
}
int b63 (char *s, char *r, int n) {
unsigned char c1, c2, c3; int b;
for (b=0; n>0; n-=3, b+=2) {
c1 = *s++;
c2 = *s++;
*r++ = c63[c1 >> 2];
*r++ = c63[((c1 & 0x3)<< 4) | (c2 >> 4)];
if (n > 2) {
c3 = *s++, b+=2;
*r++ = c63[((c2 & 0xF) << 2) | (c3 >> 6)];
*r++ = c63[c3 & 0x3F];
} else if (n == 2)
*r++ = c63[(c2 & 0xF) << 2], b++;
}
return b;
}
int bff (char *s, char *r, int n) {
unsigned char c1, c2, c3, c4; int b;
for (b=0; n>0; n-=4, b++) {
c1 = l63[*s++], c2 = l63[*s++];
*r++ = (c1 << 2) | ((c2 & 0x30) >> 4);
if (n > 2)
c3 = l63[*s++], b++,
*r++ = ((c2 & 0x0F) << 4) | ((c3 & 0x3C) >> 2);
if (n > 3)
c4 = l63[*s++], b++,
*r++ = ((c3 & 0x03) << 6) | c4;
}
return b;
}
/* b63.c */
#include "base-63.h"
int main() {
char b[3072], c[4096]; int l, t;
while ((l=read(0, b, 3072)) > 0) {
t = b63(b, c, l);
write(1, c, t);
}
return l;
}
One day we even use our--copied--program at a computer dealership, and show off how one program does about 20 MB/sec, and the other one goes about 60 MB/sec. Yes, they are stupid, too. They try to pull off some knowledgeable quip about the optimizations of the new processor making programs optimized for that processor run so much faster. We're laughing at them, because they don't know. (Even so, this is our first taste of the wicked sin: new, faster processors stopping the worry about old, slow programs. The experience ruins about a year of our programming, as we get less elemental, and more cosmopolitan. Eventually, we'll have to throw away all that we learned in that time, if we ever want to get serious about winning the test of having the best program for a job that there is. We need to learn to ignore even the experts.)
But obviously, at least we are writing good code. It compiles cleanly, always--just look at this:
make Base64 b64 b63 cc Base64.c -o Base64 cc b64.c -o b64 cc b63.c -o b63
That we are writing good code is also evidenced by the fact that it compiles on any machine besides the one we own, and especially that it compiles on a different processor. The world for some people ends before it gets that far.
So do we know by now? Or are we like the dealership people, too?
We're tired of it by now. (We're also tired of tinny-tasting things like indentation of code, which is worse than writing good code, and much, much harder to read--and thousands of times harder to maintain.)
We write one more program, that runs at speed X on 16-bit machines, 2X on 32-bit machines, and 4X on 64-bit machines.
The graph shows each of the programs' time in seconds for encoding 100 MB of binary input into base-64 characters. StuffIt Deluxe is included for reference. The table shows the figures used in the graph. The suffix -opt refers to a program when compiled with -O3 -funroll-loops.
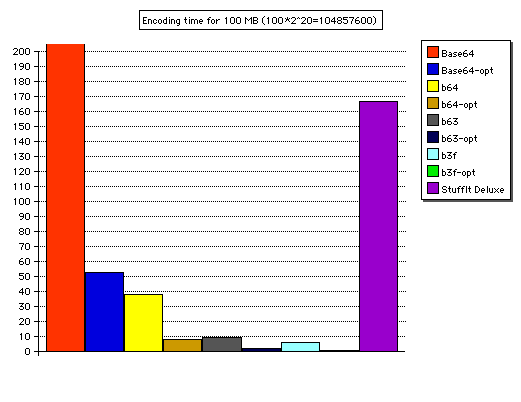
| Program | Time |
|---|---|
| StuffIt | 166.67 |
| Base64 | 207.35 |
| Base64-opt | 52.78 |
| b64 | 37.98 |
| b64-opt | 7.94 |
| b63 | 9.04 |
| b63-opt | 1.93 |
| b3f | 5.77 |
| b3f-opt | 0.88 |
The lesson is never, ever think that either a processor speed or a compiler optimization--although temptingly they give us the best from what we have--is a substitute for the best program. A powerful computer and compiler are like the water pressure in a hose. However, a longer, stronger hose takes water farther by far than water can ever spray out of the end of the hose.
Also, never assume we have the best program.
/* b3f.h */
/* Make your choice.
On 32-bit machines, int is probably faster;
on 64-bit, long long might be. */
typedef unsigned
/* short */
int
/* long long */
gen;
enum {
Z = 3072
/* preferably should be divisible by 3 and by 2 */
};
/* gen.c */
#include <stdio.h>
int main() {
char c64[65]
= "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789"
"+/";
int i;
printf("unsigned short t12[4096] = ");
printf("{16705");
for (i=1; i<4096; i++)
printf(", %d", (c64[i>>6]<<8) | (c64[i&63]));
printf("}");
printf(";\n");
return 0;
}
# configure make gen (echo '/* values.h */'; ./gen) > o.$$ \ && wrap < o.$$ > values.h \ && rm o.$$
# make rm -f b3f; make b3f
/* loop.c */
/* this one can be unrolled */
for (j=i=0; i<Z>>1; i+=3) {
/* 12 bits at a time
1) f.m[i]>>4
2) ((f.m[i]&15)<<8)|(f.m[i+1]>>8)
3) ((f.m[i+1]&255)<<4)|(f.m[i+2]>>12)
4) f.m[i+2]&4095
*/
if (sizeof(gen) == 2) {
ob.a[j++] = t12[f.m[i]>>4];
ob.a[j++] = t12[((f.m[i]&15)<<8)|(f.m[i+1]>>8)];
ob.a[j++] = t12[((f.m[i+1]&255)<<4)|(f.m[i+2]>>12)];
ob.a[j++] = t12[f.m[i+2]&4095];
} else if (sizeof(gen) == 4) {
/* note: I assume that << 16 is faster than an array lookup;
otherwise, I would have a preshifted array, so I would OR
the values from two 4,096 element arrays, instead of shifting
the value of the first one to make an integer out of the
combination of both */
ob.a[j++] = (t12[f.m[i]>>4]<<16)|t12[((f.m[i]&15)<<8)|(f.m[i+1]>>8)];
ob.a[j++] = (t12[((f.m[i+1]&255)<<4)|(f.m[i+2]>>12)]<<16)|t12[f.m[i+2]&4095];
} else if (sizeof(gen) == 8) {
ob.a[j++] = ((unsigned long long)
((t12[f.m[i]>>4]<<16)|t12[((f.m[i]&15)<<8)|(f.m[i+1]>>8)])<<32)
|((t12[((f.m[i+1]&255)<<4)|(f.m[i+2]>>12)]<<16)|t12[f.m[i+2]&4095]);
}
}
/* b3f.c */
#include <errno.h>
#include "b3f.h"
#include "values.h"
int main() {
int i, j, l, z;
union {
char b[Z];
unsigned short m[Z/2];
} f;
union {
gen a[Z*4/3/sizeof(gen)];
char b[Z*4/3];
} ob;
z = 0;
errno = 0;
do {
l = read(0, f.b+z, Z-z);
if (l < 0)
break;
z += l;
if (z < Z && l != 0)
continue;
if (z == 0)
break;
if (z < Z)
ob.b[z+1] = 0;
#include "loop.c"
i = write(1, ob.b, z*4/3);
if (i < 0)
break;
if (z%3)
write(1, ob.b+i, 1);
z = 0;
} while (l);
return errno;
}
Thankfully, we're tired of doing things those abstract experts' ways, like main(void) and NULL instead of 0.